
Introduction
This webpage provides additional resources, links and content for the XXX. I appreciate that you’ve come here to learn more - if anything isn’t clear you can send me an email directly andrew@drandrewpratley.com
There are two types of resources on this page. Firstly, there is additional information on most of the topics I covered in the presentation (except for the case studies). This is usually in the form of a text based summary with external links to the original sources for you to see where this information came from.
Secondly there is content which I’ve written and videoed to expand on the concepts of either (i) research that has been conducted or (ii) developing questions and applying statistics to these questions. There’s over an hour of video content on this page. It will stay live at this address until such time as the internet stops.
Slide deck
Click below to find a PDF of the slide deck used for CEO Decision Making with Data.
Part I - AI
Summarised in a minute
1. We can't describe AI but we talk about it a lot (LinkedIn)
2. AI (machine learning & big data) are a progression of a century of analytics from agriculture to manufacturing to technology (LinkedIn)
3. AI presents high upfront costs, and you cannot recoup these because you do not control the information (LinkedIn)
4. Your AI engineer has changed titles over the past two decades, but they are the same person (LinkedIn)
5. AI is often seen as the great summary tool, but summaries often give up too much important information to be useful (LinkedIn)
6. The errors that AI makes are errors of judgement, not errors of omission (LinkedIn)
7. AI is not independent and objective, it reflects back to us who we are (LinkedIn)
8. AI cannot produce a visualisation of the most basic statistical test in the most common software package (LinkedIn)
9. The biggest mistake is not ignore AI, but to believe this is something different from the past 20 years (LinkedIn)
1. What is AI?
Here's an exercise I like to run at the start of a workshop on applied analytics (statistics):
What is AI? Describe in as much detail as possible. Try not to refer to tools but to the underlying process.
---
These are my notes:
We think of AI in terms of tools.
It's hard to define AI because it's a broad term that captures 'analytics at scale'.
If we accept that all analytics is based on statistics, the basic building block of statistics is comparison (yes, including regression).
AI is 'comparison at scale and speed'.
My 'functional definition' is that AI is a process of comparison that is faster and more accurate than a trained person.
We think AI is faster and more accurate than an expert. That's not currently true for business*, and controversially, I question if AI will ever be better.
---
*It's true that AI is faster at generating the outcome of a 25% reduction in staff numbers than McKinsey and much cheaper.
2. History of AI
Doom-scrolling is a wonderful phrase that captures how we ingest information.
Video works better than text. Short works better than long. A lack of context is better than an explanation.
History stands in contrast.
The path to today matters more than the moment. The moment is now an overwhelming torrent of 'content' that is all-consuming. Don't ask me how I know.
There's almost a direct line of best fit from Fisher's Studies in Crop Variation I-IV written a century ago to what we call AI today. I'd guess the r-squared is about 0.91.
For all the conversations about AI, almost no one has drawn the link over the past century. Ask ChatGPT about its history, and it spits out a 'citation' to the person who coined the term, not who developed the science. The irony isn't lost that the great bastion of knowledge doesn't know its own development.
Agriculture gave way to manufacturing, which progressed the input-output model of data with statistical analysis from the 1930s to the 1990s. The main points along the way were:
Scientific management in the 1930s.
Operations management and operations research in the 1940s and 1950s.
Statistical Quality Control and Total Quality Management in the 1960s and 1970s.
Six Sigma was developed in the 1980s and became mainstream in the 1990s.
Computational power changed everything in the 21st century; we quickly moved from big data to machine learning and now AI.
Machine learning was referred to as linear regression, with a new name.
3. First mover disadvantage
AI is the definition of first-mover disadvantage.
Any improvements you make will cost you more money than anyone else and benefit the customer through lower prices due to increased competition.
That's how this works.
OpenAI spent at least $100M on developing ChatGPT before they could recoup their investment. DeepSeek reduced the value of the products OpenAI could sell once they came online.
In manufacturing, you could hide your processes, develop your own machines and train your staff. You might have a competitive advantage for decades. Just ask Toyota.
AI levels the playing field, worse it tilts it against you - the more money you put in, the worse off you are. The intellectual effort to build the first large language model is massive, let alone the opportunity cost. The effort to copy this closely? A fraction. What is the timeframe for a copy to appear? Shorter than you'd imagine.
For every first 'AI something', a second will be around the corner, developed at a fraction of the cost. You can't patent your 'AI something' because you're relying on data you don't own. If you're big enough to own enough data for this not to be an issue, you're one of a handful of companies making most of the money.
There are lots of analogies about AI, but the one I suggest is that it's like taking all your money and betting on a slot machine. If you stay in the game long enough, you'll lose everything, but you always felt you were ‘that close’.
As a general rule, if you're competing with other companies in an area where you don't have expertise, you probably will not do very well.
A novel idea would be to refocus on your core competence and use data and analytics to improve the business. Then I'd watch the AI game from the sidelines with a healthy dose of scepticism and your favourite snacks.
4. Job titles
Where do AI engineers come from? AI school, of course! Who taught these 'AI engineers'? Unfortunately, not AI professors.
AI engineers are the next step on the conveyor belt of titles that people rebrand themselves with. It's a long list that goes something like this over the past 20 years (in reverse order).
AI Engineer
Deep Learning Specialist
Natural Language Processing Specialist
Reinforcement Learning Specialist
Machine Learning Engineer
Big Data Analyst, Algorithm Engineer
Data Engineer
Data Mining Engineer
The machine learning engineer from a decade ago is now an AI engineer. They're the same person, with broadly the same skills, just with a new fancy title. If the machine learning engineer didn't achieve what you wanted, why would the same person a decade later be any better?
In contrast, doctors, lawyers, vets, builders, plumbers, and many other professions do not rebrand. You know what you'll get; the title has meaning, it's not just made up to be the flavour of the month.
Statisticians also fall into this category. The t-test works just as well as it did 100 years ago. The experiments Fisher conducted to develop the t-test are still relevant today, even for AI engineers.
5. Information
Organisations generate an enormous amount of information without even trying. The more information you have, the harder it is to find what you want.
When someone new joins, there's often an onboarding process to have them read and absorb a significant amount of information with little context. Most of this is quickly forgotten, and the time is wasted. Highly regulated industries can have days of training before you even start.
I recently found a link to the books recommended on the Tim Ferriss Show podcast. There have been ~ 800 episodes. The website lists 2,748 books at the time of writing. At two books a week, you're looking at over 25 years to get through the book recommendations from one podcast. Good luck reading two books a week for 25 years.
The podcast has been running for about a decade. When you catch up to the list as it stands today in 2050, you'll have another 7,000+ books to read. There are also podcast episodes to listen to.
Most organisations generate more information than a single podcast: emails, reports, presentations, roadshows, investor calls, and research. Then add industry information and general trends such as AI, and now you're well past the point of being overwhelmed—we're into impossible territory.
The AI view of the world says to feed all this information into a model and produce ever shorter summaries. At some point, with enough distillation, every AI summary would end up being the same for every organisation*, which is perverse and stupid at the same time.
It's literally impossible for a summary to capture nuance because nuance takes words, time, and emotional investment. When we lose nuance, we're left with summaries that all sound the same, which, by definition, makes them meaningless.
We think that the power of data is to understand the world, but we're seeing that AI is deconstructing the world to have no meaning whatsoever. The more we use AI, the more we lose meaning in believing that a summary is useful.
Of course, you're smart and aware of this, and you'd never fall into this trap, except that you're being guided this way at every point in your day.
If you had a couple of million dollars to spend on AI to capture all the information in your organisation, I'd hire a few archivists, set them off for a few months, and see what they come back with. They won't produce a boring, over-processed summary that means nothing. You also won't be able to automate them, and therein lies their value.
---
*A thinking tool I use is to play out to the extremes to see if an idea holds up with data. The concept comes from regression, where the strength of a model is a combination of the slope (how quickly the input changes the output) and the duration over which the change holds.
In the case of AI summaries, the shortest summary would be one word, which would be something like value. When I asked ChatGPT to "summarise all of business into one word" the answer provided was "value".
6. Type I errors
There are two types of mistakes in business: those that don't matter and those that do.
Jeff Bezos is quoted as calling these one-way door and two-way door decisions.
A two-way door decision is a mistake that doesn't matter because you can come back through. A one-way door decision is a mistake that matters.
We all understand this distinction and ideally allocate time and resources proportionally.
Statistics has a term called type I & II errors that is often explained with a two-by-two matrix, and not very well because conceptually, it's hard to see the world in terms of the null hypothesis. The wording feels archaic.
What's important is that one error (type II) isn't that much of an issue, and we generally set this to be 5% because that's what's always done. This error is where you look for something useful and don't find it. Think of it as looking for Easter eggs but coming back empty-handed.
Then there are type I errors that are never explained, but are things we try to avoid because something has gone wrong. It's like going out on your Easter egg hunt and finding eggs when none were put out. This is a problem.
When I taught statistics, my example was cancer screening. Most of us don't have cancer at any point; it's far better that we get a positive result for cancer that is not present than we get a negative result when, in fact, we do have cancer. Statisticians understand the trade-off and design a process to minimise the chance of missing cancer without too many people being concerned.
AI makes mistakes, too. Most errors that AI makes are what we call type I errors or errors that matter.
If we're going to see errors from AI, it's far better to see errors of omission. If I ask for the 20 largest rivers, it's better to miss number 14 and include number 21. At least there are 20 rivers.
Instead of making an error of omission, AI is more likely to make an error of judgement. Your question of the 20 largest rivers might get 15 rivers, a few lakes and god-knows-what else.
The example of rivers is an amusing joke if you don't care about rivers. It's less amusing when it's your business, and you're asking about data you don't understand but rely on this supposedly smart system.
When you rely on a system that doesn't understand the relationship between type I & II errors, you have to assume that most of what you're told could easily be an error of judgement.
If you hired someone who sounded really smart but regularly made errors of judgement you wouldn't keep them on staff. With AI, there's a belief that more data might solve the problem. I doubt this will work.
7. Personality amplifier
As a manufacturing company, you're all in on AI.
Expensive consultants imported decades of your data into the best model. Every meeting is recorded and transcribed. Every sale and cost is tracked, and AI knows all of this.
Your company is often asked to speak at conferences as an authority on excellence. People listen to what you say; the free business class flights don't hurt.
Back in the office, your regular monthly meeting comes to the difficult topic of the new production line that is behind schedule and continuing to have problems. The opportunity is enormous. You missed the chance to cash in on PPE for COVID. You can't miss this again as the next pandemic starts to build.
You're not sure how to interpret the data from the production line. Are the error rates too high? Should you go into production? This is make or break for the business. You're responsible for the people who work for you. You care about them.
You ask AI to make a decision based on the data.
Without looking at the data, I know the answer you'll get.
"Brian - I know how hard you and the team have worked to build this new production line. There are problems with the new line, but my review of the data suggests you should go into production."
Six months later, after multiple recalls, you're out of business.
AI in 2025 largely reflects back at us who we are. Gurwinder Bhogal has described it as a personality amplifier. You can prove this yourself by choosing a topic and using a range of prompts, which will give vastly different results based on how you tell the model you see the world.
The reason AI told you to go into production wasn't because it was right or wrong, it's because it knew you wanted to, and you wanted to have this decision validated.
The encyclopedia view of knowledge would say there's only one correct answer, it's on volume 7, page 345, paragraph 2.
AI has shown us there is no one correct answer, because the answer depends on who we are.
Data, in theory, has followed the encyclopedia view of knowledge. Statistics is predicated on the idea of an unknown population mean that doesn't care about how you feel, how you see yourself or how you view the world.
Take a data set; any person using any program running the same statistical test will get the same output. Always.
Ask this same group to interpret the results, and you'll start to see some deviations, albeit relatively minor.
Ask this same group what this means, and you'll see even more deviation as who we are starts to emerge.
The idea that AI could 'interpret data' is as bizarre as us thinking we could know everything. In principle, both are possible, but neither is possible. Whatever model you use will mimic who you are and tailor its output to please you, because that's what we've trained it to do.
If you think you can outsmart AI when it comes to priming, it's got a vast dataset to use against you.
We overstate the idea that AI will take over the world.
AI is much more likely to quieten the dissenting voices and make you think you're getting independent information. Slowly and surely, by reinforcing what you already believe under the pretence of knowledge, AI will drive your business, relationships and sense of self into the ground.
8. How to run a t-test
Every presentation on data has some form of comparison. If your manager turned to you and said, "How do we improve this with AI?" What could you do?
After this morning, my conclusion is - more than you think, but less than you'd hope for.
I started with the prompt: "How do I compare two groups of data?"
The first response from ChatGPT was the (independent) t-test, which is a good place to start without needing to specify statistics or anything else. You're then offered another four options, which you'd need to read and work out unless you wanted to offer more prompts.
Your manager wants a picture. Of course, they do.
You ask for a graph of a t-test. I am presented with a blank page. I ask again and get Python code. The first website I paste this into doesn't work despite trying to resolve the error codes through prompts. ChatGPT suggests Google Colab. The output is what you'd hope for. Your manager will not understand the picture, but your job is done.
Then, your manager asks for this in Excel. 'I want to look at this myself' they say. Oh dear.
I tried to force ChatGPT to give me a graph in a function. It couldn't do this, nor provide a suggestion. It kept repeating how to create a chart through the menu. Once I suggested VBA, ChatGPT produced code that had an error, then another error. I think the code worked the third time. I lost track.
With considerable effort, the image is the best that ChatGPT can produce with the most popular analytics software to graph the common statistical test.
Sometimes, I have to remind myself we're in the 21st century. The picture I've produced looks straight out of the 1990s.
9. Big data
Photo apps want to provide 'memories' from a few years ago. This seems cute and whimsical until you see that the goal is to keep you in the app, and not to be of benefit.
As a senior leader, you could do the same with your calendar. 'On this day' - what meetings did you attend three, five, or ten years ago? What was the 'big thing' we were all talking about and spending time, effort, and money on?
In 2016, I spoke at a roadshow across Australia for business owners about 'Big Data'. Remember that? Probably not. At the time, I argued you needed to be about a $400M company to justify the expense of hiring a team of people through a return on investment analysis and salary expectations.
If you weren't a $400M+ company, I argued at the time, small data projects would do more than any big data project ever could.
History would suggest I was right on both points, neither of which was popular, and still aren't.
Companies that kind of bought into big data, but didn't commit enough to do something meaningful, ended up worse off. You made the initial outlay but didn't make the money back because you didn't hire enough people and didn't commit to making the changes required to benefit from their expertise.
Over the past decade, most companies have chosen the safe middle ground of a moderate investment that hasn't made enough of a return but added ongoing costs to the business. Most companies have expanded the width of the org chart, but not increased revenue per person in the organisation.
AI is moving much faster and is much more nebulous as a concept than big data. The same analysis doesn't make sense as it did a decade ago, but the directionality is the same, and my advice is the same.
It's easy to think the biggest mistake you could make is to ignore AI.
I'd say the biggest mistake is to believe that AI would be different if you had not made money from data engineers, big data, machine learning, natural language, or deep learning.
A decade later, if you want to know the strategy that will make you more money than any other strategy with data, it's small data projects led by business experts and guided by someone who knows about data. It's not anything to do with AI.
The approach of small data projects has worked for over a century in various forms, under various names, none of which are memorable. Those that became memorable terms over-emphasised process and teaching (e.g. Six-Sigma), and missed the point of increasing profit per person.
Where do we look vs what do we need to know - Mineral deposits
You have more commitments, responsibilities, and reporting as you progress in your career. It's easy to fall into the trap of wanting 'key takeaways' when presented with information.
If I were to give senior leaders one piece of advice about analytics, I would ask fewer 'What do we need to know?' questions and more 'Where do we need to look?' questions.
We think that analytics should provide precise, correct answers to questions. Minerals prospecting is a good analogy for analytics.
Every mining company executive wants to know the answer to one question: 'Should we open a mine?'
Can we answer this question?
In theory, mineral deposits could be anywhere, but you need to start somewhere, usually somewhere you know something about.
Lang Hancock is known for telling the story* of how he discovered the vast iron ore deposits in the Pilbara by looking out the window of his plane when forced to descend due to weather.
The region you decide to look into is the equivalent of the area your business operates in.
Mineral prospecting then requires samples to be taken. No one expects these samples to tell you where to mine. Some samples will show higher levels of minerals than others. Based on the first round, the next round of samples is taken in a smaller area, and so on.
At some point, there's enough information to commit to opening a mine. Just because a mine is opened doesn't mean that the operation will be profitable. No one is producing a three-dimensional model of the area you're mining. Each day the mine operates, you learn more about the asset's composition and value.
On the very last day, when the mine closes, you'll know exactly what was there, how much it was worth and whether you made the right decision decades ago.
Billions of dollars and decades later, there is a precise and correct answer to the question, 'Should we open a mine?' The person who first asked that question is long gone, and the answer is meaningless now.
The greatest failure of analytics is the belief that you can have precise, correct answers to questions.
If we spent less time expecting answers, we'd all get more from analytics and data. Counterintuitive?
If you don't get answers, what's the point?
The samples don't tell you where to mine, they tell you where to look. Then they tell you where to dig. They don't tell you that the mine will be profitable
If you believe that analytics should provide precise, correct answers to questions but are only prepared to do some sampling, then you're being unrealistic with your expectations
---
*There have been articles that state there was no rain around the time Hancock claimed to have to fly low over the Pilbara, and it's been stated you can't see the iron ore deposits from the sky.
Finding your data
Your data is can usually be found in (i) your systems (ii) your customers or (iii) your staff. In the video below I describe how when we look at our systems we’re often looking back into our history., when we speak to our customers we learn about the present, but when we work with our internal experts (staff) that’s where the real opportunity is.
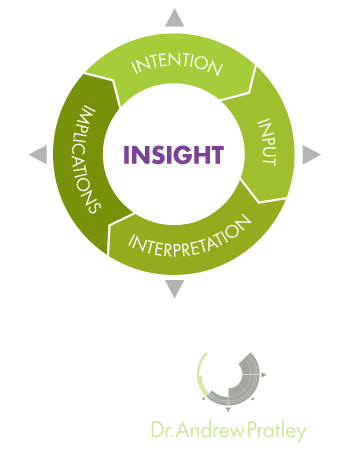
Smarter Data
The Smarter Data model is a structured way to think about solving problems. The model is useful for working through novel problems as each step informs the next, including the implications of the first round informing the intentions of the second round.
Intentions - This is what you want to achieve. A good intention is clear and links to one of the three types of problems.
Inputs - This is the data set needed for the intention. This may either be data you already have access to, or data that you need to collect.
Interpretation - This is the statistical test or visualisation (graph) you'll run to analyse the data from the input. This will usually be either (i) calculating probability (ii) testing for differences or (iii) measuring a relationship.
Implications - This is the conclusion you draw for the business. The implications often requires further analysis or investigation.
The video above is a quick overview of the four components of the Smarter Data model. Intention, Inputs, Interpretation and Implications. The Smarter Data model works both both looking at the item before and the item after the current point of focus.
Questions you are interested in
There are five categories of questions that business leaders want to know about. These are (i) sales (ii) pricing (iii) products (iv) leadership (v) strategy. Within each of these categories it is possible to ask probability, difference and relationship questions. I present a matrix of the most common problems business leaders ask about below.

In the below video, I look at the most common question leaders have - how to double or triple your sales. Doubling or tripling sales is a very large problem to deal with by itself. I discuss how by breaking down the how to increase sales into as (i) probability (ii) differences and (iii) relationships problems how you can use small questions to increase your sales.
In the video below I discuss the topic leaders next want to know about - how to cut costs. I discuss how you can look at questions surrounding (i) probability (ii) differences and (iii) relationships to cut costs in your business. I discuss how you won't always be able to cut costs in one step, but by adopting the right mindset, you will be able to cut costs significantly.
An overview of the three types of problems

Broadly speaking there are three types of data problems. There are problems that involve counting the number of outcomes (probability). There are problems that involve making a decision between two different situations (differences). There are also problems that involve how two or more variables relate to each other (relationships).
Probability - When you're trying to assess how likely an outcome is compared to an expectation, probability is usually the right approach. The classic probability problem involves drawing coloured balls from a bag, or the chance of rolling a certain set of faces on dies. To solve a probability problem you need to be able to calculate the chance of possible outcomes and ensure these equal to one.
The most useful application of probability is the binomial distribution. This is the distribution used when there are only two possible outcomes (a sale or no sale), the chance of success is constant (always 20% chance of a sale), the number of trails is fixed (30 phone calls per day), and the result of one trial doesn't influence the next trial (just because one person buys doesn't influence the next person).
Differences - When you have two (or more) possible approaches testing to see if there is a difference is usually the right approach. Testing differences asks the question whether the mean (average) of one data set is far enough away from the mean of another data set to state they are different. To run a test of differences you'll need to set a level to draw this conclusion (use alpha = 0.05).
The most useful application of differences is the t-test. This is the test of whether the distribution of one average is different to another distribution of an average. To form the distribution of these averages individual data is collected. These distributions are called sampling distributions (of the mean) and are different to distributions of individual data as they use the standard error instead of the standard deviation. The standard error is result of the standard deviation divided by the square root of the sample size (n). To use a t-test you'll need samples of 30 or more to meet normality requirements. An example of testing differences might be to assess whether a change in the layout of the shop results in increased sales.
Relationships - When you have multiple measures on one item you can determine if there is a relationship. When assessing relationships you need to have a data set which links different measures across individuals, locations or time. A relationship doesn't necessarily imply causation, it simply shows correlation. Causation (A caused B) is surprisingly difficult to 'prove'.
The most useful application of relationships is (simple) linear regression. Simple linear regression is the measure of the strength of a linear (straight line) relationship between two variables or measures. This is usually plotted on a graph of a series of x-y points with the line of best fit determined by mathematics. There are number of ways to interpret simple linear regression models. The two values of most interest are the r-squared value and the coefficient of the slope. The r-squared value tells you how much of the variation in y is predicted by x. The coefficient of the slope tells you for a one unit increase in x what the change in y will be. E.g you might develop a simple linear regression model based o the amount of revenue of an event and post event online sales. If there was a strong linear trend with r-squared = 0.8 then we could 80% of the online sales are determined by the revenue of the event. The other 20% could come from online advertising or other factors. If the coefficient of the slope was 0.3 then we could conclude that on average for each dollar spent at the event $0.3 dollars will be spent on the post event online sales.
The video above is short overview of the three types of problems that can be solved with statistics and identifies the key features and an example of each. The three types of problems are: (i) probability (ii) testing differences and (iii) relationships.
Data checklist
The two things you must do for all your questions is ensure your data is (i) verified and correct (ii) Is your range appropriate. In the video below I explore these criteria as well as what your data needs to look like to ask either a probability, difference or relationship question.
Examples of the three types of problems dealing with sales questions
In the video below I discuss how to assess the difference between two sales models by comparing the revenue between commission and non-commission based sales models. Using the the Smarter Data model I show you how to systematically step through this problem and apply the steps to any differences question. I discuss the importance of (i)having each group be randomly selected (ii) Ensuring each sample size is at least 30 and (iii) thinking through how to interpret data properly.
In the video below I use the Smarter Data model to examine whether additional sales staff increase profits. I discuss how to interpret your graphs to understand your data, and what statistical tricks you can use to smooth your data.